Problemy wyszukiwarek: do czego służy system CBIR
Rozwiązaniem problemów związanych z wyszukiwaniem zdjęć może się okazać system CBIR (Content Based Image Retrieval) wyszukujący obrazy na podstawie ich zawartości. Z punktu widzenia użytkownika systemy CBIR można podzielić na dwie grupy. W pierwszej, QBVE (Query By Visual Example, wyszukiwanie na bazie próbki obrazu), użytkownik wskazuje systemowi obraz podobny do poszukiwanego. W drugiej, QBSE (Query By Semantic Example, wyszukiwanie na bazie frazy), podaje frazę lub całe zdanie opisujące poszukiwany plik. Druga metoda wyszukiwania jest bardziej skomplikowana ze względu na, wbrew pozorom, wyższy poziom abstrakcji, jednak jest ona dla użytkownika łatwiejsza do zrozumienia.
Obie metody wyszukiwania obrazu mają poważne ograniczenia, w ciągu ostatniej dekady algorytmy były stopniowo udoskonalane.
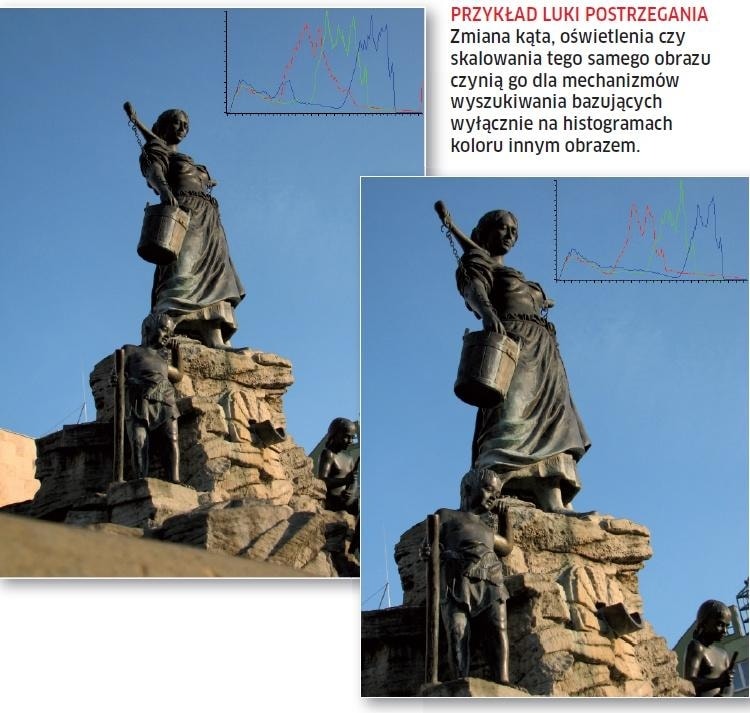
Pierwsze podręcznikowe wyzwanie dla systemów CBIR to tzw. luka postrzegania. Jest to różnica między rzeczywistym wyglądem danej rzeczy a informacją opracowaną na podstawie cyfrowej jej interpretacji. To co dla człowieka jest fotografią zwykłej plaży, dla komputera oznacza serię bajtów. Trudno więc o wzajemne zrozumienie. Problemem jest też tzw. luka semantyczna oznaczająca brak zbieżności między informacją opracowaną na podstawie analizy obrazu a jej interpretacją przez użytkownika w różnych okolicznościach. Mało tego – istnieje przecież mnóstwo takich obiektów, które są znane tylko niektórym grupom społecznym. Ponadto obiekty te mogą być różnie interpretowane, w zależności od kontekstu. Interpretacje zaś mogą mieć wiele synonimów w języku naturalnym.

Techniki wyszukiwania zdjęć: jak działa CBIR
Prace nad metodami realizacji systemów CBIR rozpoczęły się na dobre na początku lat 90. XX wieku. Dotychczas opracowano kilka różnych identyfikatorów (deskryptorów), a w ich ramach – kilka różnych metod i technik. Współczesne cyfrowe zdjęcie składa się z kilkunastu milionów pikseli. Porównywanie wszystkich, piksel po pikselu nawet przy obecnych mocach obliczeniowych komputerów jest zadaniem nierealnym.
Z tego powodu stosuje się uproszczenie, dobierając pewną właściwość (lub właściwości) cyfrowego obrazu, umożliwiające wygenerowanie krótszego ciągu bajtów (tzw. wektora cech), który pozwala maksymalnie jednoznacznie zidentyfikować interesujący nas obraz. Podczas wyszukiwania podobnego zdjęcia proces ten rozpoczyna się od wygenerowania wektora cech na podstawie wybranego identyfikatora, porównania go z innymi wektorami cech obrazów umieszczonych w bazie, a następnie pogrupowania i zobrazowania wyników.

Jak wyszukiwarka widzi barwy: identyfikator koloru
Rozpoznawanie barw ma duże znaczenie, ponieważ ludzkie oko postrzega obrazy, przywiązując większą wagę do koloru niż kształtu czy wzoru. Ta cecha wzroku oraz ośrodka widzenia w mózgu umożliwiła opracowanie algorytmów redukujących rozmiary zdjęć i filmów bez zauważalnej utraty jakości. Ułatwia również rozróżnianie cech obrazu.
Większość formatów zapisu obrazu przechowuje dane o kolorach pikseli w trzech bajtach, opisujących nasycenie składowych RGB i rozróżnienie wynikających z tego 16 777 216 barw. Taka notacja często jest wykorzystywana w systemie CBIR, ponieważ przyspiesza wyszukiwanie. Niestety w małym stopniu oddaje sposób postrzegania kolorów przez człowieka. Inne przestrzenie kolorów (np. HSV, HSB, HSL, HSI) również zapisują barwy w postaci trzech bajtów na punkt, jednak określają mieszankę barwy, jej nasycenia oraz jej jasności, co lepiej odpowiada percepcji wzroku człowieka. Wybór konkretnej przestrzeni kolorów zależy od celów stawianych zarówno systemowi CBIR, jak i jego budowy. Przyspieszenie wydzielania cech obrazu odbywa się poprzez tzw. kwantowanie przestrzeni kolorów, proces identyczny z ograniczaniem liczby kolorów w obrazie bez stosowania filtrów zmniejszających błąd kwantyzacji (np. dithering).
Najprostszą prezentacją treści obrazu jest jego histogram. Aby go utworzyć, wystarczy zliczyć wszystkie równe sobie wartości pikseli w obrazie dla każdej ze składowych koloru osobno. Histogram ma jednak poważne ograniczenie – nie prezentuje rozkładu przestrzennego kolorów. Okazuje się, że różne obrazy przedstawiające ten sam obiekt mogą mieć odbiegające od siebie histogramy albo różne obrazy mogą generować podobne histogramy. Technika ta może być jednak zastosowana do obrazu podzielonego na bloki o stałych rozmiarach, do których zostaną utworzone osobne histogramy. Takie rozwiązanie powiększa jednak ilość informacji przechowywanych w wektorze cech.
Inną metodą jest generowanie wektora spójności koloru (Color Coherence Vector), którego wyrazy określają, czy dany słupek histogramu tworzą punkty leżące w sąsiedztwie, czy też nie. Zaletą histogramów jest ich niska wrażliwość na operacje obrotów, przesunięć i skalowania oraz niska złożoność obliczeniowa.
W celu wyizolowania przestrzennych zależności między punktami w obrazie stosuje się miary momentów statystycznych (wariancja, kowariancja, dystrybuanta, średnia, współczynnik korelacji itp.). Metody te, podobnie jak w przypadku histogramów, stosuje się najczęściej do wydzielonych fragmentów obrazu.
Rozpoznawanie wzorców: identyfikator tekstury
Droga od ogółu do szczegółu prowadzi poprzez wydzielanie charakterystycznych cech obiektów. Niezbędne są więc metody podziału obrazu jednolite pod kątem wybranych własności regiony. To tzw. segmentacja, a wyniki jej działania umożliwiają zastosowanie lokalnych identyfikatorów. Segmentacja jest najtrudniejszym do wykonania elementem systemu CBIR – wykorzystuje się w niej metody punktowe, obszarowe i krawędziowe.
Najpopularniejsze z metod to segmentacja wododziałowa, progowanie, klasteryzacja, segmentacja oparta na regionach lub punktach kluczowych. Przykładowo w progowaniu ignorowane są relacje przestrzenne obrazu, co oznacza, że łatwo wykluczyć elementy obiektu różniące się barwą, ale stanowiące jego część. Złożoność obliczeniowa wzrasta w przypadku obrazów kolorowych.
Tekstura to wycinek obrazu zawierający wzór o pewnych cechach. Do wydzielania jego cech stosuje się miary statystyczne, modele Markowa oraz metody spektralne (transformata falkowa, kosinusowa, filtry splotowe Gabora). W przypadku zastosowania miar statystycznych używa się histogramu, momentów statycznych, średnich jasności, a także wariancji kontrastu.

Wyodrębnianie obiektów: identyfikator kształtu
Identyfikatory kształtu są wrażliwe na przesunięcia, obroty i zniekształcenia. Ponadto powinny mieć niską złożoność obliczeniową. Rozpoznawanie kształtów bazuje na wyszukiwaniu krawędzi i regionów. W tym celu stosuje się momenty geometryczne, kody łańcuchowe, metodę siatkową, szkielet obszaru, triangulację, liczby Eulera, a także sygnatury.
W przypadku metody siatkowej, po przeprowadzeniu segmentacji obrazu, interesujący nas fragment umieszcza się na siatce o ustalonej rozdzielczości, a następnie oznacza wszystkie fragmenty, w których wystąpiła granica obiektu. Wadą tej metody jest duża wielkość wektora cech. Kody łańcuchowe lokują kształt na siatce o umownej rozdzielczości, jednak w tym przypadku kształt rozciąga się do najbliższego elementu siatki. Po obraniu dowolnego węzła i zmiany kierunków są numerowane. Kody łańcuchowe mogą być numerowane od 0 do 3 (czterokierunkowe) lub od 0 do 7 (ośmiokierunkowe).
Wyszukiwanie: porównanie cech
Po wydzieleniu cech obrazu wskazanego przez użytkownika oraz obrazów zawartych w kolekcji można przystąpić do porównywania ich wektorów. Równania wektorów cech nazywane są metrykami odległości. Jeśli w systemie CBIR używamy identyfikatorów opartych na histogramach, do porównań najlepiej wykorzystać metryki Minkowskiego oraz metryki kwadratowe. Pierwsza porównuje wyłącznie odpowiadające sobie słupki histogramu, sumując ich różnicę. Ponieważ mierzy siłę braku podobieństwa pomiędzy histogramami, zawodzi przy pomiarze podobieństw. Druga popularna metryka, zastosowana w systemie QBIC firmy IBM, porównuje również nieodpowiadające sobie słupki histogramu pod względem ich podobieństwa. Jest bardziej efektywna, jednak konieczność pomiaru poziomów słupków histogramu w układzie każdy z każdym jest kosztowna pod względem obliczeń.

Precyzowanie zapytań i prezentacja wyników
System CBIR umożliwia użytkownikowi zawężanie kręgu poszukiwań poprzez wskazywanie np. obszaru zainteresowania lub wyboru punktów odniesienia. Kolejność prezentacji odnalezionych fotografii jest najczęściej klasyfikowana na podstawie ich podobieństwa. Ale nie jest to jedyny sposób, zdjęcia mogą być prezentowane chronologicznie, hierarchicznie oraz grupowane – to najbardziej atrakcyjna wizualnie formą prezentowania wyników, stosowana w celu przyśpieszenia pracy systemu CBIR.
Dotychczas z powodzeniem zastosowano metodę siatki z obrazami, metodę koncentryczną (w której obrazy bliższe sobie pod względem podobieństwa leżą bliżej siebie w rezultatach wyszukiwania) oraz metodę spiralną, która umieszcza kolejne wyniki wyszukiwania na obrzeżu spirali, coraz dalej od jej centrum, w którym znajduje się wzorcowy obraz.
Systemy wyszukiwania: jak poprawić rezultaty
Na jakość wyszukiwarki grafiki składa się szybkość działania i efektywność. Szybkość zależy od złożoności obliczeniowej algorytmów. Drugi czynnik, efektywność, nie może obyć się bez oceny człowieka, nie istnieje bowiem algorytm modelujący idealnie nasze preferencje. Nawet ludzie nie są zgodni co do tego, co widzą na obrazie i jak go interpretują, więc oczekiwanie, iż maszyna poradzi sobie lepiej, byłoby nierozsądne.
Na początku rozwoju badań CBIR nie istniały sposoby obiektywnej oceny. Badacze testowali algorytmy na własnych kolekcjach zdjęć. Z biegiem czasu pojawiły się jednak takie standardy, jak Corel Photo CD, które były dostępne głównie profesjonalistom. Brak ocen amatorów zakłócał wyniki działania wyszukiwarek. Dopiero rozwój Internetu umożliwił powstanie złożonych i efektywnych systemów wyszukiwania. I to właśnie użytkownicy stali się najbardziej wymagającymi jurorami, odpowiadając na pytanie, jak trafne były wyniki wyszukiwania, a także wskazując w wynikach istotne i niepotrzebne rezultaty.